

MeltanoLabs; Analyst Success; Federated Computational Governance; ThDPTh #45
MeltanoLabs; Analyst Success; Federated Computational Governance; ThDPTh #45


Some longer-form writing bug bit me this week. I for some reason ended up writing three big data points about MeltanoLabs, Federated Computational Governance, and response to Tristan Handys latest newsletter.
Read about it below…
I’m Sven, I collect “Data Points” to help understand & shape the future, one powered by data.
Svens Thoughts
If you only have 30 seconds to spare, here is what I would consider actionable insights for investors, data leaders, and data company founders.
- Federated Computational Governance is there to stay. The concept stemming from the data mesh paradigm will stay and will generate new business models and new challenges.
- Meltano launches MeltanoLabs, but isn’t thinking far enough. MeltanoLabs is another effort of Meltano to start building a platform, which they must do in some way. They are thinking deep and hard about that process but seem to not get to a point that will rival Airbyte, at least not in the platform building capabilities which are likely to be the deciding element in the data integration market.
- Different forces in the data integration market are analyzed below. There are a few different types of network effects in play in the data integration market, so I decided to take some time to map them out below, and you can do so too!
- There are three concrete items a data integration company will have to leverage to become the biggest platform. See below, and remember, in a network effect-driven market, there will only be one platform — the biggest one.
- Analysts should not measure themselves at all. Instead, IMHO the right way to measure analysts, just like a development team, is to measure the output of the decision-making unit. So to put it into other words: “If you’re an analyst in a product team, you’re successful if your product team is kicking ass.”
Federated Computational Governance
🔮 What: Confluent has a nice short explanation of the principle of “federated computational governance — govern data wherever it is”, together with a few examples. While federated computational governance is a concept that stems from the data mesh paradigm, the idea is pretty simple and extends beyond any specific paradigm. The idea is simple, once we decentralize data ownership, we will still need to govern it. But centralized governance will not work with decentralized ownership, to govern completely decentralized obviously is beside the point, so we end up with federated governance.
Since doing federated governance “manually” sounds neither feasible nor scalable, it should be computational — or automatic. And that’s it.
🐰 My perspective: For some reason, if you google for “federated computational governance” you get some quote about it being a “team of data product owners” which doesn’t really be very general, and neither like a “must be”.
Let’s take a small example to truly understand this. I think the hardest concept of the data mesh paradigm: Let us build a super small data mesh: A small git repository containing CSVs.
Let’s decentralize ownership: Give every autonomous team push rights to their respective “folder” inside the git repository. So now, teams can completely autonomously push data into the data mesh.
But wait! Someone just pushed in lots of personalized information, that’s not good! Let’s introduce some governance. Put up a small “BestPractices.MD” with a section “How to handle data sensitively”, and invite the teams to submit pull requests to that.
Perfect, we just federated the data governance.
The question only is, how do we truly control this? How about instead of giving teams push rights we let them create pull requests? Does that sound like a solution? I hope not, because it would take away a lot of autonomy and pretty much destroy the network effects we would gain by running a data mesh.
So? The only good option here is to have some automatic way of checking the pushed data, like a git-hook scanning for X@Y.Z patterns, or something like that. So let’s implement that and congratulations, we just added the computational to the federated governance!
At our destination: So we quickly arrived at our destination, federated computational governance. I hope the trade-off, and the key questions become apparent to you. How decentralized should this be? How much do we want to control? How much freedom do we have to take away to gain which kind of value by making the meshwork together?
Can I ignore this if I am small? The problem with governance is, for a data mesh, it is what keeps it “meshy”. If your mesh is small, actually consisting of CSVs, but the CSVs have no way of joining together because people keep messing up the conformed dimensions used for joining, your data mesh becomes pretty worthless. So there is no way around federated computational governance if you’re implementing a data mesh.
Now, this might sound like something that is only important in the data mesh context, but I think it already is kind of alive in a lot of companies extracting data at scale, not specifically following a data mesh paradigm. Most machine learning systems in fact will run in a mostly decentralized way, exposing data through APIs, just as most dashboards created by decentralized data analysts which all too often produce data governance issues.
Additionally, federated computational governance opens up a lot of business opportunities, because automatic data classification, identification, access right monitoring isn’t something that is covered by many solutions out there, but it should.
developer.confluent.io • Share
☀️ What: Taylor A. Murphy goes into explaining the four different connector ownership models, a nice deep dive which is a promising start to building a platform. The models are:
Single named owner — made for a clearly identifiable owner.
Vendor self-managed — meaning the provider of the source/database/whatever also provides the tap.
benevolent community member — as the name says
Meltano supported community contributions — basically the previous one but with a lot of support (in everything BUT developing) from the company Meltano.
MeltanoLabs is the place for the new fourth model.
🐰 My perspective: First of all, I find it really great that Meltano does such a deep dive into understanding the types of connectors. I also find it important that they realize they need to make it easier for developers to contribute & to maintain connectors.
I just feel they are putting way not enough thought into building the actual platform & ecosystem behind the connectors. These four models basically say “we would like you to build connectors because you’re a good person”.
This is not going to scale at all, and it’s not going to compete with Airbyte who at least realized that economic incentives are an important mechanism to get people to contribute.
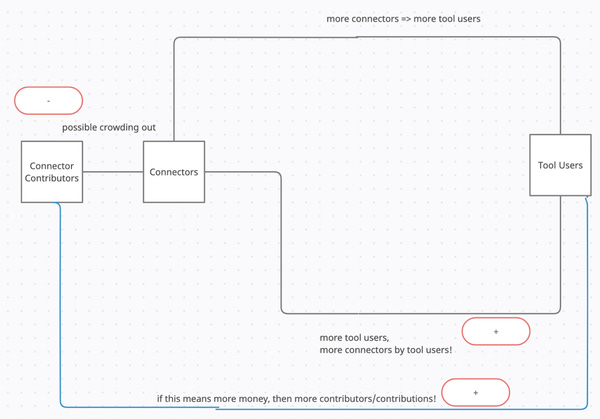
The dynamics in the data integration market are really simple, it’s a two-sided platform-like market:
- one side being the users of the data integration tools — companies
- the other side being the providers or connectors.
The market is dominated by cross-side network effects, meaning more customers mean more connectors will be developed, more connectors mean more customers. But only if we do one thing: Incentivise the connector creators in a way correlated with the number of users. E.g. by paying based on user numbers.
A second network effect is that customers themselves often modify & contribute connectors — which can be seen as a same-sided network effect.
Finally, a possible negative same-side network effect is the emergence of larger connection development companies which might crowd out smaller ones.
Ok, so once we understand the dynamics, what should companies in this space do? Well, it’s simple,
1. Do everything to leverage the first network effect by giving ALL money to the contributors.
2. Leverage the second network effect by making it super easy for customers to contribute connectors (this is a bit of what the MeltanoLabs is about)
3. Design incentives in a way that maximizes the value gained from the connectors, which should be a measure of Quality + number of connectors. Airbyte is moving in that direction by providing quality scores, but of course, there are much more direct measures like influencing the filtering options & listing inside the “store”; Running features on well-maintained connectors, providing high-quality connectors yourself, and many more.
Tristan Handy on One-Way Doors
😍 What: The “Analytics Engineering Roundup” is still (after some recent changes) a great newsletter, run by Tristan Handy and now supported by a few additional equally great authors.
In a recent edition, Tristan Handy explores the idea of “one-way vs. two-way doors”, meaning decisions that are easy to revert vs. ones that are hard to revert.
If the decision is easy to revert, speed counts. If it is hard to revert, then the decision process is essential.
Tristan argues that data people have to take one-way doors into account. For two-way door decisions, their job is to speed up decisions, for one-way doors, it is about quality.
🐰 My perspective: Time keeps on moving. And the world isn’t like a decision theory lecture in university, where we get a set of options “A, B, C” and then maximize expected value.
There simply are no true two-way door decisions, you’ll be at a different point in time, and things will have changed inevitably.
But every decision can be made to be more two-way-doory, if we invest the time, data & brainpower. Equally, every decision can expand from alternatives A, B to C, D, E if we invest time, data & brainpower.
The true question from my perspective for every decision is: How hard is it to make this decision two-way-doory? And how hard is it to expand it to more options? Compared to the downsides.
That’s it.
However, in my feeling, this perspective is a bit different than what Tristan and Benn have in mind. But I find it valuable and I do find it in the scope of data people to offer data to expand the scope of decisions or tell us about how hard/easy certain data pieces are to procure. In fact, these are some of the most strategic ideas you can offer to a company — think about CapitalOne who spent years and years just on a journey to procure data, to transform their business completely.
So should analysts measure their work on the speed of decisions made? Or should they take into account whether it’s a two-way or one-way decision and have two measures for success? I don’t think either option is a good one. From my perspective neither speed of decisions, nor the quality of the decision process are good indicators of an analyst’s work, as outlined above neither measure is an indicator for good work IMHO.
I actually think, just as you should focus on evaluating development teams as units, and not as a random collection of individuals, you should evaluate the decision-making unit, not an individual’s contribution to the decisions. And that does simply mean, you’re a great product analyst if your product team is kicking ass. Period.
🎄 Thanks!
Thanks for reading this far! I’d also love it if you shared this newsletter with people whom you think might be interested in it.
Data will power every piece of our existence in the near future. I collect “Data Points” to help understand & shape this future.
If you want to support this, please share it on Twitter, LinkedIn, or Facebook.
And of course, leave feedback if you have a strong opinion about the newsletter! So?
It is terrible | It’s pretty bad | average newsletter… | good content… | I love it, will forward!!!
P.S.: I share things that matter, not the most recent ones. I share books, research papers, and tools. I try to provide a simple way of understanding all these things. I tend to be opinionated. You can always hit the unsubscribe button!
Data; Business Intelligence; Machine Learning, Artificial Intelligence; Everything about what powers our future.
In order to unsubscribe, click here.
If you were forwarded this newsletter and you like it, you can subscribe here.
Powered by Revue