

Finding business models for data companies, staying up to date, building open source; ThDPTh #78
Finding business models for data companies, staying up to date, building open source; ThDPTh #78

I’m Sven, and this is the Three Data Point Thursday. We’re talking about how to build data companies, how to build great data-heavy products & tactics of high-performance data teams. I’ve also co-authored a book about the data mesh part of that.
Time to Read: 5 mins
Another week of data thoughts:
Data start-ups should start to provide more e2e solutions, not just technical “best in class” atomic solutions.
Zingg Labs just turned one and is on that exact break point
In the data space, it’s best to not stay up to date at all
Open source business models are still all over the place
🐰🐰🐰🐰🐰🐰🐰🐰🐰🐰🐰🐰🐰🐰🐰
Zingg turns one, what managed offering to build?
What: Zingg is an open source entity resolution tool. Founded by Sonal Goyal and now powered by her start-up Zingg Labs. Sonal shares interesting benchmark numbers for the solution they built. It’s an interesting problem as the solution faces a quadratic growth in processing time based on the number of entities to resolve. Based on the shared numbers, Zingg seems to solve this problem well.
Zingg Labs is now working on building out their managed offering.
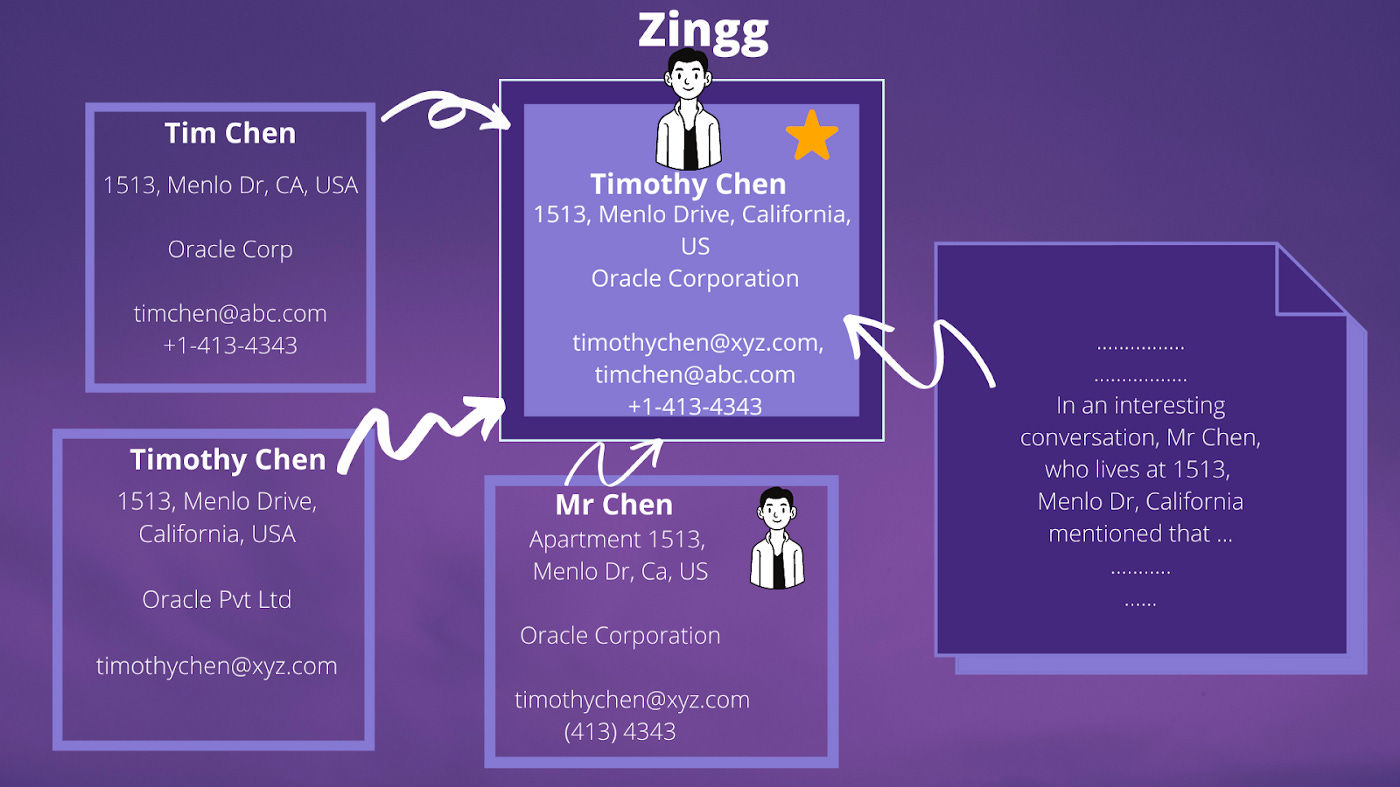
My perspective: I mentioned Zingg before in Jan 2022 and I still think my comments on Zingg hold true. The solution they use becomes better the more data it has available. In other words, if set up nicely, the value of using Zingg could grow with each user, sparking network effects.
I’m also interested in what kind of managed offering Zingg Labs cooks up because they are set up to leverage the exponential growth of data better than most other data start-ups.
Broadly I would divide the possible options into two categories.
(1) The “deep vertical slice”
Computing quadratic problems is hard right? So Zingg Labs might take the computation out of the users’ space and do it on their space, essentially enabling people to create an account, and talk to an API endpoint to get entities resolved.
This means that companies are free to use the entity resolution wherever they want because it’s all code & API.
Zingg would focus on making the entity resolution best in class, faster, better,... the managed solution would essentially dig (vertically) into one specific part of the journey of data.
But there is another solution.
(2) The “light horizontal end-to-end” slice
The alternative is building an end-to-end solution. That means figuring out where companies usually:
(1) Get the entities to be resolved from?
(2) Use the resolved entities in?
(Complete brainstorming mode turned on now, without any knowledge on this particular market) A possible end-to-end solution could look like this:
1. You get a Zingg paid account
2. Plug in your Salesforce, Hubspot & database credentials
4. Zingg takes care of the rest, publishes a resolved entity model back to your database
5. Zingg also exposes a dashboard to your Tableau instance
6. Zingg provides an API your other services can use to retrieve the entities with extreme speed.
Why I think you should default to the “light horizontal e2e slice”
For some reason, people tend to think the horizontal slice is more effort than the vertical slice, but in my experience it is not. That’s just a question of feature & technical scoping. It is however harder to do for founding teams that have a strong technical background, founders that have a bias for going deep into the technical side of things and don’t like to stub & prototype things along the way.
Given that the effort is roughly equal, why should you default to the horizontal e2e slice?
The simple truth is, data is growing exponentially, but the value derived from it is not distributed equally. Data has to go through a pipe of generation, collection, possible consolidation/ingestion to a central place, transformation into information,.... And only at the end value is created.
If you build a database start-up you’re just building a storage solution. That only captures the full value of the exponential growth, if everything around you is keeping up the pace. If everything around you is growing just as fast, and connectors to your solution are being built quickly.
If you choose to build the horizontal e2e slice however, you’re in for the full ride from the very beginning.
Yes, it’s harder for founding teams with technical background, but there is a reason most AI unicorns provide these kinds of horizontal slices. Even databricks & snowflake, both traditionally more of a “deep vertical slice” are taking over the whole pipe.
Building Open Source
What: “As Mike Volpi from Index Ventures noted at the Index Open Source Summit (2021): “It took Mongo DB 10 years to derive the business model they run now and monetize successfully…” Wow, 10 years to somewhat successful monetization – and that is one of the major open source success stories.”
This article by the team behind objectbox goes deep into open source business models. It also looks into multiple examples of successful open source companies.
“There is a lot of evidence that open source companies struggle with open source models and licenses – this is also true for successful companies. There is no “Red Hat Model” – just selling services has rarely worked”
My perspective: I find this to be one of the more thorough reads on business open source. But I don’t like the framing of the authors “the struggle of turning open source into a business”. In my opinion, the important question is the other way around.
The key question is how to utilize open source for business.
Resource: https://objectbox.io/building-a-business-on-open-source/
How To Stay Up To Date
What: Marie Lefevre shares her framework for staying up to date with data, as data is such a fast moving category. It consists of “define what you’re looking for”, “find out where to look”, “find the time” and “keep only the essential”.
My perspective: Marie’s framework sounds great for keeping up-to-date with the data space. It truly is a fast moving place.
However, for data professionals, data engineers, analytics engineers, data scientists, I feel like the right advice is to simply not stay up to date at all. Instead, you should do three things to deal with the ever changing data space:
1. Build things modular, so you can replace them every 6 months.
2. Experiment, and count on having to run new experiments every time you do something (not just something new).
3. Do a deep dive, whenever you’re starting something new or touch a topic again after 6 months.
Because the reality is, in a fast changing environment, most things are just noise. If you stay up to date, you'll end up replacing knowledge piece after knowledge piece until you have nothing left of the things you “stayed up to date with”.
Resource: https://towardsdatascience.com/how-to-stay-up-to-date-in-the-field-of-data-1f108d123dfb
What did you think of this edition?
🐰 It is terrible ( = I just made it to this link b.c. I was looking for the unsubscribe button)
Want to recommend this or have this post public?
This newsletter isn’t a secret society, it’s just in private mode… You may still recommend & forward it to others. Just send me their e-mail, ping me on Twitter/LinkedIn and I’ll add them to the list.
If you really want to share one post in the open, again, just poke me and I’ll likely publish it on medium as well so you can share it with the world.