

Dark Data; Thoughtful Friday #27
Dark Data; Thoughtful Friday #27
6 Categories of data you should know, and why dark data matters after all.

I’m Sven and I’m writing this to help you (1) build excellent data companies, (2) build great data-heavy products, (3) become a high-performance data team & (4) build great things with open source.
Every other Friday, I share deeper rough thoughts on the data world.
Let’s dive in!

“Gartner defines dark data as the information assets organizations collect, process and store during regular business activities, but generally fail to use for other purposes (for example, analytics, business relationships, and direct monetizing).” (Gartner Glossary)
Descriptions and definitions around dark data are all over the place, they only agree on one thing: “dark data is data that is collected & stored but not seen/analyzed”.
Just like dark matter.
Invisible, there, and it holds the universe together.
So what is a useful way of thinking about “dark data”?

Not all “dark data” is created equal. One part is not analyzed, because it carries no information relevant to our business.
The other part is not analyzed, because it is not analyzed, because we haven’t seen the value that is there.
But that’s not all, once you get to this point, you see lines blur…
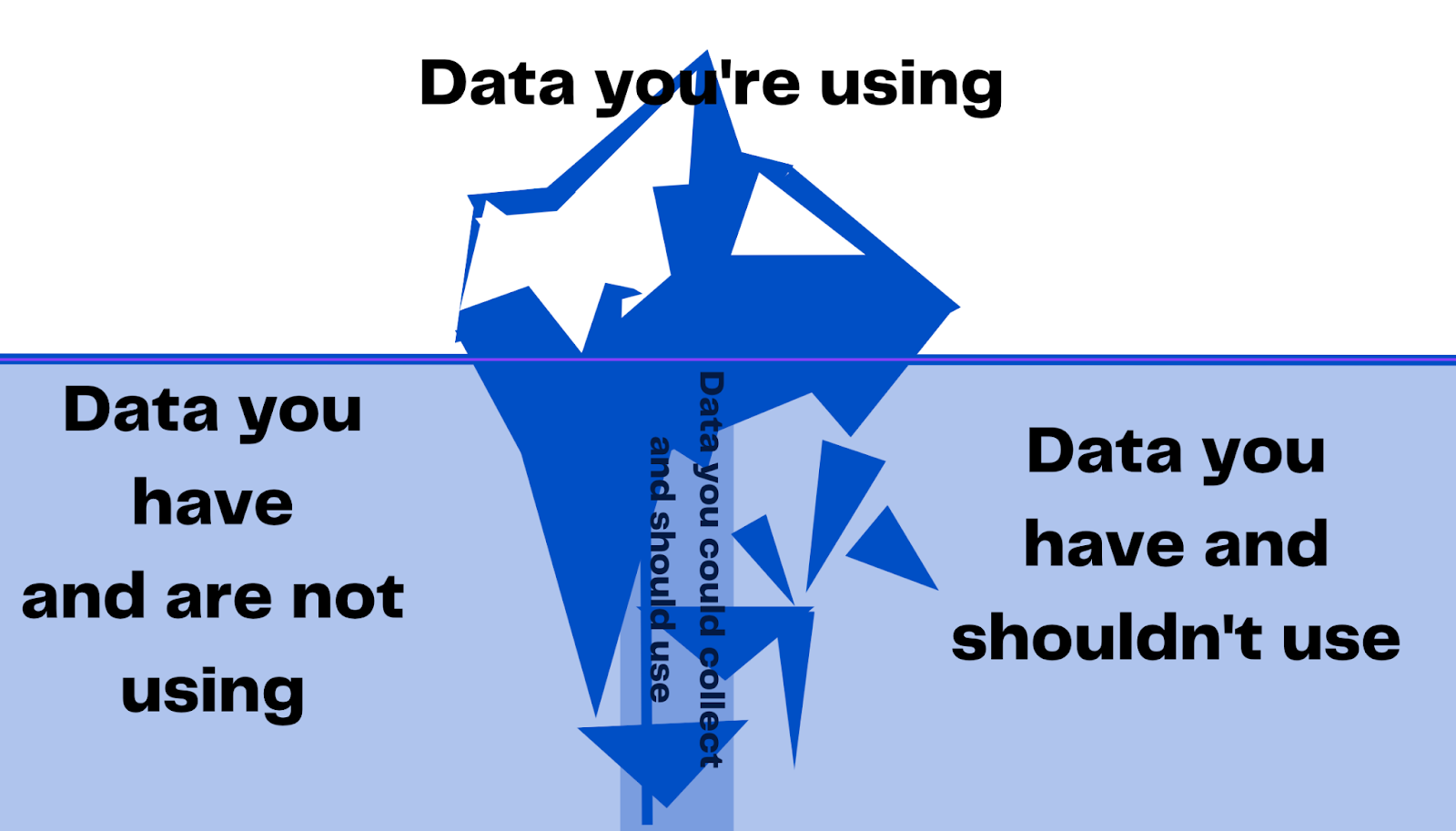
Suddenly we can see four categories of data with very blurry lines.
Data we are using, data we should be using and have but are not. Data we should collect and could collect, but are not. And data we have but shouldn’t use.
Already sounds difficult?
Well, how about external data?

So there we got an appropriate “dark data” iceberg landscape:
Data you’re using ( A) internally self-collected or B) externally collected & procured)
The data you have are not used but should be
Data you could collect are not but should
Data you have and shouldn’t use
Data you don’t have and shouldn’t collect ;)
While this doesn’t make “dark data” clearer, I like to keep in mind that there is much more to data than just used data or “dark data”.
You need more data
The more information you get, the more likely your company is to be successful.
The amount of information has three drivers:
The amount of data
The native information-richness of the data
Your company’s ability to extract information from this data
*Of course “information” really is “information that is valuable to your business, industry, context”.
Dark data will matter
While most definitions of dark data try to tell you it’s bad and costly, dark data is actually more like dark matter.
Four things control this:
Your company’s ability to extract value changes over time
Your company’s definition of value in data changes over time
Your company likely has no idea what information really is inside “dark data” and what “dark data” actually exists.
You HAVE dark data, while you do not have other data. Data acquisition is costly.
Value extraction changes over time: Your company might become better at working with unstructured data. Dark data often is unstructured, so once your company hits that point, reconsider what “dark data” you have and whether you might be able to turn it into something useful.
Logfiles might turn into a cyber security solution. Transaction histories might turn into a smart fraud detection tool.
Value changes over time: You create new products, your industry changes, and decision and action spaces change. Thus the relevant information and the value of the ones you have changed all the time.
No idea what dark data there is: Since dark data is basically defined as the data you don’t know much about, it is quite likely that you’re underestimating its value.
Underestimation of external data procurement: This is particularly problematic when coupled with the fact, that you’re also likely to underestimate the cost of either collecting additional data or procuring high-quality data externally.
The key to data is unique data
It’s not just about having data, or more data. If the data is available to everyone, there’s no additional benefit for you.
The key is to have data that others do not have. And is by definition either expensive to procure, or collected by yourself, and thus possibly dark data.
Dark data is more like dark matter than anything else, potentially just as useful as all the other data.
How was it?
New articles by me:
I did some serious coding work to get a tutorial on functional engineering out. “Experience the benefits of functional data engineering firsthand in a simple Airflow & Python-based Setup. Convert a regular data pipeline to a functional one in two simple steps.”
Shameless plugs of things by me:
Check out Data Mesh in Action (co-author, book)
and Build a Small Dockerized Data Mesh (author, liveProject in Python).
And on Medium with more unique content.
I truly believe that you can take a lot of shortcuts by reading pieces from people with real experience that are able to condense their wisdom into words.
And that’s what I’m collecting here, little pieces of wisdom from other smart people.
You’re welcome to email me with questions or raise issues I should discuss. If you know a great topic, let me know about it.
If you feel like this might be worthwhile to someone else, go ahead and pass it along, finding good reads is always a hard challenge, and they will appreciate it.
Until next week,
Sven
Question - doesn't actively collecting potential dark data run the risk of a "data swamp" ?